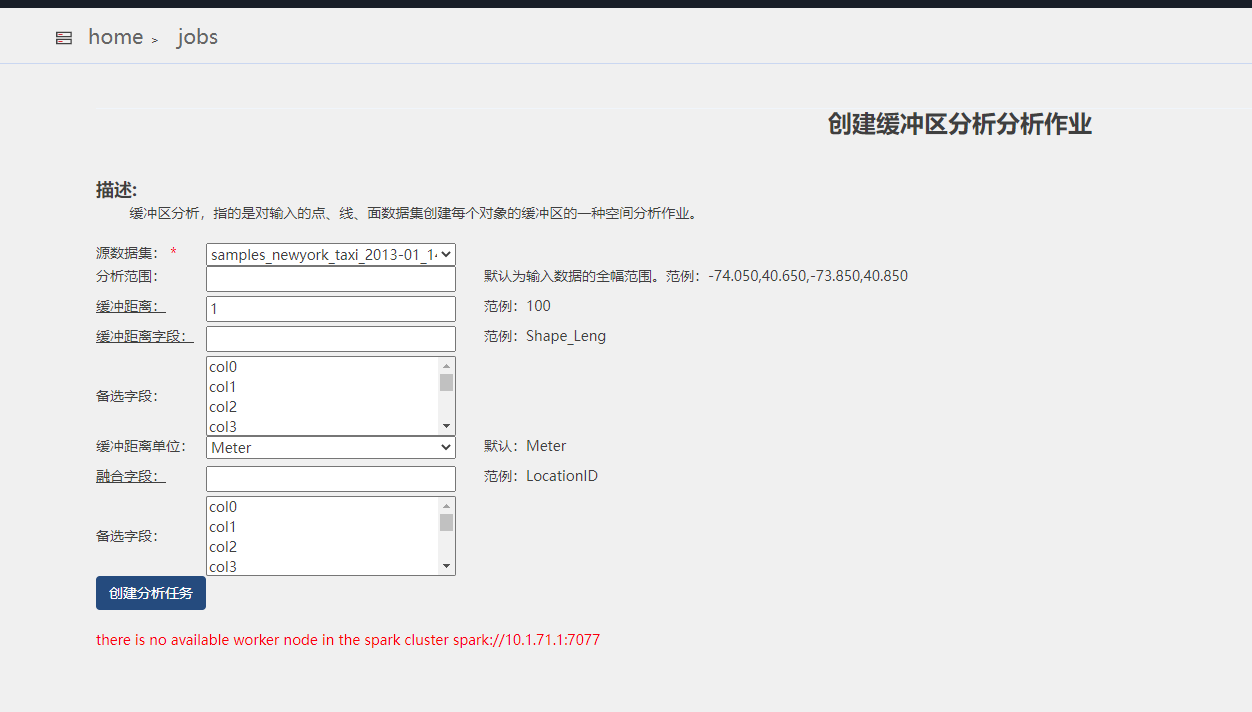
使用产品:iserver 11i 操作系统:win10 x64 问题详细描述:原来使用的本地spark,现在改为使用其他的分布式计算集群Spark,用示例数据做缓冲分析提示错误there is no available worker node in the spark cluster spark://10.1.71.1:7077。
您好,您检查一下集群页面worker是否添加成功并且状态为ALIVE,如果没有状态为alive的worker则会出现该报错。如果目前并没有可用worker的话,您可以在主节点iserver中通过集群-》加入集群-》添加报告器并保存的方式加入集群(注意需要勾选是否分布式分析节点),本机部署服务地址使用主节点本机地址,实际使用可将地址改为实际ip和端口。spark正常状态如下:
您看一下执行任务时network里面对应应用ID.json,里面是否有报错消息
这种请求很多,其中个别请求会有异常,具体错误信息如下:
Job aborted due to stage failure: Task 0 in stage 0.0 failed 4 times, most recent failure: Lost task 0.3 in stage 0.0 (TID 3, 10.1.71.2, executor 2): java.io.StreamCorruptedException: invalid stream header: 73720025 at java.io.ObjectInputStream.readStreamHeader(ObjectInputStream.java:862) at java.io.ObjectInputStream.<init>(ObjectInputStream.java:354) at org.apache.spark.serializer.JavaDeserializationStream$$anon$1.<init>(JavaSerializer.scala:63) at org.apache.spark.serializer.JavaDeserializationStream.<init>(JavaSerializer.scala:63) at org.apache.spark.serializer.JavaSerializerInstance.deserializeStream(JavaSerializer.scala:126) at org.apache.spark.serializer.JavaSerializerInstance.deserialize(JavaSerializer.scala:113) at org.apache.spark.executor.Executor$TaskRunner.run(Executor.scala:370) at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149) at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624) at java.lang.Thread.run(Thread.java:748)
错误信息如下,会不会是spark访问不到这个示例数据导致的呢?另外从本地spark改为外部spark之后,iServer控制台一直提示连接master异常信息(上面有截图),一段时间后iServer程序会自动退出。 {"id":"3c97fd38_9111_4f97_a93d_19ec1c8705ff","state":{"errorStackTrace":null,"endState":true,"startTime":1666249722995,"endTime":1666249815938,"publisherelapsedTime":0,"runState":"FAILED","errorMsg":"Job aborted due to stage failure: Task 0 in stage 0.0 failed 4 times, most recent failure: Lost task 0.3 in stage 0.0 (TID 3, 10.1.71.2, executor 2): java.io.StreamCorruptedException: invalid stream header: 73720025\n\tat java.io.ObjectInputStream.readStreamHeader(ObjectInputStream.java:862)\n\tat java.io.ObjectInputStream.<init>(ObjectInputStream.java:354)\n\tat org.apache.spark.serializer.JavaDeserializationStream$$anon$1.<init>(JavaSerializer.scala:63)\n\tat org.apache.spark.serializer.JavaDeserializationStream.<init>(JavaSerializer.scala:63)\n\tat org.apache.spark.serializer.JavaSerializerInstance.deserializeStream(JavaSerializer.scala:126)\n\tat org.apache.spark.serializer.JavaSerializerInstance.deserialize(JavaSerializer.scala:113)\n\tat org.apache.spark.executor.Executor$TaskRunner.run(Executor.scala:370)\n\tat java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149)\n\tat java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)\n\tat java.lang.Thread.run(Thread.java:748)\n\nDriver stacktrace:","elapsedTime":90401},"setting":{"DEFAULT_MASTER_ADRESS":"local[*] ","referToken":"NmTs56U0xlv0_ctrsNGgKLRtPZMDBUaO9Df9xCDAHZhaPtjoLYS_4qYUAS_2E70AzDc9W_OsehQx6e7ngGFJTg..","mainClass":null,"appName":null,"serviceInfo":null,"output":{"resultEpsgCode":3857,"outputPath":null,"datasourcePath":"E:\\soft\\supermap-iserver-11.0.0-windows-x64\\webapps\\iserver\\processingResultData\\Analyst\\udbs\\ce0671fd_a6ac_43d6_89e6_0821fe924800","datasetName":"analystResult","type":"UDB"},"args":null,"input":{"datasetName":"samples_newyork_taxi_2013-01_14k","numSlices":0,"specField":null,"datasetInfo":{"metaInfo":"{\n \"HasHeader\": false,\n \"FieldInfos\": [\n {\n \"name\": \"col0\",\n \"type\": \"WTEXT\"\n },\n {\n \"name\": \"col1\",\n \"type\": \"WTEXT\"\n },\n {\n \"name\": \"col2\",\n \"type\": \"WTEXT\"\n },\n {\n \"name\": \"col3\",\n \"type\": \"INT32\"\n },\n {\n \"name\": \"col4\",\n \"type\": \"WTEXT\"\n },\n {\n \"name\": \"col5\",\n \"type\": \"WTEXT\"\n },\n {\n \"name\": \"col6\",\n \"type\": \"WTEXT\"\n },\n {\n \"name\": \"col7\",\n \"type\": \"INT32\"\n },\n {\n \"name\": \"col8\",\n \"type\": \"INT32\"\n },\n {\n \"name\": \"col9\",\n \"type\": \"DOUBLE\"\n },\n {\n \"name\": \"X\",\n \"type\": \"DOUBLE\"\n },\n {\n \"name\": \"Y\",\n \"type\": \"DOUBLE\"\n },\n {\n \"name\": \"col12\",\n \"type\": \"DOUBLE\"\n },\n {\n \"name\": \"col13\",\n \"type\": \"DOUBLE\"\n }\n ],\n \"GeometryType\": \"POINT\",\n \"StorageType\": \"XYColumn\",\n \"PrjCoordsys\": 4326\n}","firstRowIsHead":false,"xIndex":10,"available":true,"name":"samples_newyork_taxi_2013-01_14k","prjCoordsys":0,"yIndex":11,"fieldInfo":[{"name":"col0","type":"WTEXT"},{"name":"col1","type":"WTEXT"},{"name":"col2","type":"WTEXT"},{"name":"col3","type":"INT32"},{"name":"col4","type":"WTEXT"},{"name":"col5","type":"WTEXT"},{"name":"col6","type":"WTEXT"},{"name":"col7","type":"INT32"},{"name":"col8","type":"INT32"},{"name":"col9","type":"DOUBLE"},{"name":"X","type":"DOUBLE"},{"name":"Y","type":"DOUBLE"},{"name":"col12","type":"DOUBLE"},{"name":"col13","type":"DOUBLE"}],"type":"CSV","separator":",","url":"../../samples/data/ProcessingData/newyork_taxi_2013-01_14k.csv"}},"sparkLogFile":null,"analyst":{"distanceUnit":"Meter","distance":"1","bounds":"","distanceField":"","dissolveField":""},"contextSetting":null,"referServicesAddress":"http://10.1.88.4:8090/iserver","referServicesType":"ISERVER"}}
您用的示例数据是个csv文件,可以看看文件是否有权限;如果同样的示例数据同样的参数操作本地spark执行成功,但是自己搭建的spark执行失败的话应该还是搭建的spark的问题。您自己搭建的Spark 的版本需要与 iServer 内置的一致,同时,Hadoop 版本也需要与其对应。iserver自带的spark版本以及Hadoop 版本可以在iserver安装包\support\spark\README.md文件中查看。例如iserver内置版本为:Spark 2.3.4 built for Hadoop 2.7.3,因此使用的 Hadoop 版本应为 2.7.3